This blog contains my compiled notes for NAACL 2019 at Minneapolis, Minnesota.
- 0602 Sun:
- Tutorial: Measuring and modeling language change
- Tutorial: Adversarial NLP
- Tutorial: NLI
- Tutorial: Language learning & procesing in human and machines
- 0603 Mon:
- Keynote: language as a mirror of society
- Session 1A: Cogitive
- Panel: Careers in NLP
- Session 2: Dialogues & discourse
- Session 3: Poster: biomed applications
- 0604 Tue:
- Session 4D: Poster: Discourse, IR, MT, Vision & Robo
- Session 5A: Multilingual NLP
- Keynote: When computers spot the lie and humans do not
- Session 6D: Question & Answering
- 0605 Wed:
- Keynote: Building ML apps that humans can use
- Session 7F: Posters: ML
- Session 8E: Bio & Clinical
- Session 9D: Cognitive & Psycholinguistics
- 0606 Thu:
- Tutorial: SemEval & *SEM & DISRPT
- 0607 Fri:
- Tutorial: ClinicalNLP
0602 Sun
Morning Tutorial: measuring and modeling language change
Jacob Einstein
Slides and notebooks at github
1. Motivations
Observe language changes at long / short time scales.
What changed?
- Systemic change. e.g., in grammars
- Usage change: what people decided to talk about
Weinreich, Labox, and Herzog (1968) present five problems:
- constraints
- transition
- embedding (what implications does a change have for the larger linguistic system?)
- evlauation (social meaning of a particular change?)
- actuation (why this change, and why now?)
Sources of information about language change
- corpora
- lexicons: list of word types or cognate sets
- simulation: simple models and their ability to explain observed phenomena
- apparent time: differences between individuals by age
Language changes beyond linguistics
- computational soical sciences (text-as-data)
- digital humanities (distant reading)
- human-computer interaction (social computing)
Most of these fields are interested in explanation, not prediction.
- NLP can play an important role by operationalizing variables of interest
- Rigorously evaluating explanations is different and usually harder than evaluating predictions, and requires a different way of thinkinb.
2. Five practical methods and case studies
2.1 Word frequency
Culturomics: quantitative analysis of culture using milliosn of digitized book (Google 2011?)
Plot the frequencies of words:
- Which words?
- Which texts?
- What to count?
- Word frequencies and events have timestamps, but did one really cause the other?
(Liberman 2010): “s” vs. “f” in OCR -> might be getting the wrong string from Google Books.
Composition effects:
- Scientific aticles occupy an increasing proportion of Google Books over time.
Artisanal corpora
- Corpus of Historical American English (COHA)
- British …
Case study 1: Golder and Macy 2011: Diurnal and seasonal mood vary with work, sleep, and daylength across diverse cultures.
- Main question: how does mood shift across ths day, week, and season?
- Text: positive and negative affect lexicons from LIWC.
2.2 Difference
Questions including:
- Is political polarization increasing?
- Is polarizing becoming more about identity groups than policy ideas?
- Are gender roles becoming less stereotypical in fiction?
Quantifying differences:
- Measure word frequencies. Relies fairly directly on the original data, but word frequencies are high-variance and not really IID.
- Latent topics. Aggregates related words, but may depend on idiosyncrasies of prepocessing and hyperparameters.
- Classifier accuracies. Powerful classifiers can relax IID assumption, but are computationally expensive and sensitive to dataset design.
Information theoretic measures of difference.
- Entropy: how oncentrated is probability mass over words / topics.
2.3 Word meanings
Change in the lexicon
- Changes in a corpus may be driven by new real-world events and entities (e.g., email, tablet)
- Linguistic ‘fashions’ involve new signs for existing meanings (e.g., lol)
- …
Meaning change in distributional semantics
- Hypothesis: if the meaning of word w is summarized by a distributional representation $u_M$. Then the change in meaning should be reflected by changes in $u_M$.
Properties in word embeddings:
- Fixed-lengthe vector
- Similar words appear with large cosine similarity
2.4 Leaders and Followers
- How does a change propagate in a community of speakers? More specifically, who leads? Who follows? Who resists?
- Estimating influence from diachronic data. E.g., Kalman filter / smoother, generalized Kalman, Dynamic topic model, Gaussian Process, multivariate Kawkes processes, point process models
2.5 Cause and effect
- Text as cause, text as sequence.
- Gold standard: randomized control trial (RCT), but are expensive, unethical, and (most likely) impossible in the large-scale social experiment scenario.
- Model: Granger causation of function shifts
3. Next steps
Elaborate the connection between lexical change and other forms of systemic language change.
- Contrasting lexical and phonological change
- Measuring syntactic change: specific constructions, POS trigrams
- How good is syntactic analysis on historical text?
Make NLP systems more robust to language change, without labeling thousands of documents. - Construct validity challenges
- Other collaborative models
Allow non-specialists in the humanties and social sciences to tell NLP systems what they want without labeling thousands of exmaples.
Tutorial: NLI
Slides: this site
Tutorial: Adversarial Learning
Slides: google drive
Tutorial: Transfer learning in NLP
Slides: google slides
Tutorial: Language learning and processing in people and machines
Human lanauge acquisition
How do children learn language? (from a lot of noisy and ambiguous inputs)
Is language learned? How?
Empiricism vs. Nativism
Behaviorism vs. Cognitivism
Domain-general vs. Domain-specific learning
Functionalism vs. Formalism (language for communication)Is language learning effortless?
Takes children 5 years (14,600h if 8 hrs per day)
Takeaways: should AI models make the same mistakes as children? Should we model all the domains of learning at the same time?Learning mechanisms.
- Babies as statistical learners (Saffran et al, Science 1996: children can determine word boundaries)
Statistical learning in other domains - Babies as rule learners.
- Babies as social learners.
learning about words
Learning the systems
- Language is productive (both syntactic and morphological)
- Syntax: leavel of abstraction
e.g., “Rita drinks milk”. “agent -> action -> theme” is one level of abstraction. But “Rita resembles Ray” does not fit in this level of abstraction. Another level can be “noun -> verb -> noun”. - Syntax: type of structure. Is human language use even hierarchical? Or are they just sequential?
- Morphology. Children learn morphology earlier when language is morphologically righ (Peters, 1995) Easy morphemes to learn: frequent, fixed form and relative position to stem, clear function.
Do children know grammatical rules?
- Early word combinations are systematic
- There are overgeneralization errors
Human language processing
E.g., “The woman brought the knife into the kitchen tripped.” This is a somewhat surprising sentence.
Human’s cognitive state in processing texts.
Identification of sequential input of words are highly incremental. IN other words, humans start processing the words even before hearing the second phonemes of them.
Structural forgetting effect.
Cognitive evaluation of NLP systems
Topics:
- Applying methods from psycholinguistics and cognitive science to analyze neural networks.
- Characterizing complex human behavior around languages as a target for NLP systems.
Psycholinguistic assessment
- Treat brain as a blackbox.
- What syntactic structures are ewasy vs. hard for NN language models? (e.g., Filler-Gap dependencies. Wilcox et al., 2018, 2019)
Language evolution and emergence
- A recently-emerging exciting problem in NLP. E.g., deep RL models.
0603 Mon
Keynote: data as a mirror of society
(Nicollet Ballroom)
Statistical learning models show stereotypes.
e.g., (Caliskan et al., Science 2017), etc.
- Implicit association tests
- Universal associations in word embeddings
Propose two approaches:
Deeper understanding of human culture can help identify possible harmful stereotypes in alg systems.
- Occupatioin vs. constituency parsing descrepancies
- Racial bias in language indentification: AAE tweets are more likely to be classified as non-English.
- Is classifying some tweets as AAE a form of stereotyping? Or is that because the “English or not” training data contains mostly non-AAE?
- HireVue: Use accents, body languages, etc., for deciding on ideal candidates.
- WeSee: detect suspicious activity using data from sports, etc. E.g., to what degree is the person smiling or angry?
If data is a mirror of society, then ML models could be used like a magnifying glass to help us understand human cultures.
- Classifying words as gender specific or gender-neutral
- Word embeddings quantify 100 years of gender bias. (PNAS 2018)
- Does language merely reflect or also cause stereotypes? (What are we learning from language? PNAS 2019) Found association between bias and language usage in 25 lanugages.
1A Cognitive
(Nicollet B/C)
Entity recognition at first sight: Improving NER with eye movement information
- Hollenstein and Zhang
- Psycholinguistic evidence of fixation.
- Concatenate the gaze embeddings (eye movement features) onto word embeddings.
- Experiment on dataset:
- Eye tracking: Dundee, GEGO, ZuCo
The emergence of number and syntax units in LSTM LMs
(Lakretz et al)
- Background: Subject-verb agreement (number agreement)
- LSTM-LM information storage is controlled by the forget and input gates. But how do they track the long-distance number information?
- Datasets and probing tasks:
- Number-agreement task: (Linzen et al. 2016) and (Gulordava et al. 2018). Compare the log prob of the correct / incorrect verb occurring, given the context. There are drastic decrease in incorrect words.
- Syntac units: The tree-depth dataset (Nelson et al, 2017). Inputting the hidden representations (from pretrained LSTM LM. Gulordava et al. 2018), predict the number of open syntactic nodes at each word (if given the canonical syntactic parse of a sentence).
- Visualizing gate and cell-state dynamics.
- The singular and plural units emerged at the second layer of the network.
- Test whether subject number can be decoded (using a linear model) from the whole pattern of activities in the network, and whether this decoding is stable across time.
- Our analysis thus provides direct evidence for the claim that LSTMs trained on unannotated corpus data, despite lacking significant linguistic priors, learn to perform structure-dependent linguistic operations.
Neural Self-training through spaced repetition
(Amiri)
- Motivation: labeled data is expensive & time-consuming to obtain. -> Self-training and unsupervised pretraining.
- Self-training: boostrapping.
- Pre-training: layers are pre-trained by learning to reconstruct their inputs (autoencoder pre-training): the same neural model or parts should be used in both pretraining and fine-tuning steps. Decoupled this procedure.
- Neural self-training based on Leitner Queues, and a sampling policy learner.
- Leitner queue updating: First place all unlabeled data in the first queue. Then move instances among queues based on network predictions: promote if correctly classified; demote if otherwise.
- Harder / easier instances. Greedy data sampling approach. Select instances of the queue that most improves learner’s performance on validation data (designated queue)
- Evaluation on IMDB (subset, movie reviews) and Churn (user intention)
- Model introspection:
- Q1: What’s the issue with Highest Queues? Look at cosine similarity between representations of training instances queue instances.
- Q2: Does sample diversity matter? Compute the extent of diversity that each given queue introduces when added t o training data.
- Q3: Do we need better sampling policies? Analyze the instance movement patterns among queues.
- Conclusion: novel data sampling approach based on Leitner Queues.
Neural LMs as psycho-linguistic subjects: representations of syntactic state
(Futrell et al)
- Question: what are the actual information encoded in blacbox model hidden representations? -> Do psycholinguistics on neural network models.
- NNLM tested: JRNN (Jozefowicz et al, 2016), GRNN (Gulordava et al, 2018), RNNG (Dyer et al, 2016), TinyLSTM.
- Method: design sentences such that NN surprisals reveal representation of syntactic states. Imiporting methods and analytical tecns from the field of human sentence processing in psycholinguistics. Study a number of kinds of syntactic state, and ask:
- Do NN LMs represent the state?
- What cues do NNs use to infer the onset of the state?
- Subordinate clauses.
- Syntactic state. “Garden paths effect”.
Understanding language-elicited EEG data by predicting it from a fine-tuned LM
- Dan Schwartz and Tom Mitchell
- Different modalities of word meaning are stored in different areas in brains. Also another brain component integrates these meaning modalities.
- ERP (Event-related potentials)
Careers in NLP panel
(Nicollet Ballroom, 1-2:30pm)
- Speakers:
- Phillip Rasnik
- Judith Klavans
- Yunyao Li
- Owen Rambow
- Joel Tetreault
Some topics I remember:
Leadership
- Being an individual contributor or a team manager? Leadership is not about titles. Should relate yourselves to the rest of the community.
- Managing is different from leading. Management is not mentioned much in universities.
- Podcast: “Coaching for leaders”, “Leaders are not born; they are made”. You observe. You don’t complain; but instead come up with solutions.
- Can develop skills in grad schools. E.g., You have good ideas, but how do you deliver? How do you define projects? How do you deliver?
- Leadership is about vision and creating vision.
- You really need to learn to listen. In grad schools we don’t listen. Should make people feel they are listened to.
Time management
- How much of the non-academic things are you doing, in either academic or non-academic lives? “In Columbia, I ended up spending all time doing non-research stuffs. … doing spreadsheets, talking to people, etc.” How much time spent on emails / slack? -> Rather over-communicate.
- Count reading group as “meeting time” or “doing research”? How about coding? -> coding is definitely counted as doing research.
Career choice
- Most NLP people here does not only use blackbox NLP tools.
- Places hire you for (1) who you are, and (2) who you are going to become.
- Does domain expertise matter?
Networking
- Don’t even need to ask them to invest in a coffee time. Just need to start the conversation (or just join in random conversations. It’s totally cool.)
- Ideas. Are you concerned when you give them your ideas? IP issues w.r.t companies (especially startups)? IBM research has a collaboration structure supporting researches in univ and students.
Organizational
- How much control do junior students in your groups have? IBM example: identify projects this person can be productive. Either leverage the student’s skills, or let them develop.
- Everybody has more than one projects in IBM. Product / research projects are involved.
- Look at the micro-context. Identify: who are evaluating your works? Who are deciding the directions of works? What are they thinking? Incentives? (e.g., IP)
Work / life balances
- One reason to stay in IBM is work/life balance. Giant companies have flexibility of publication directions.
- Small companies: your research goals align highly with them.
Researches in industry
- Also government and non-profits.
- Non-profits love IPs. Govs do not. Research institutes vary…?
- Transition from e.g., post-doc into industry.
- Encourage everyone to try at least one industry internships. At least know where do the problems come from. Connect to other people.
2A Dialogue & Discourse
(Northstar A)
IMHO Fine-tuning improves claim detection
- Charkrabarty and Hidey
- Existing argumentation datasets:
- Monologue: Microtext (MT), Persuasive Essay (PE)
- Dialogue: Web discourse (WD), Change My View (CMV)
- They are small and imbalance.
- Difference in phrasing across datasets:
- MT: 50% of claim sentences contain the modal verb ‘should’. PE: propositional verbs. etc.,
- Collect 5.5 Million sentences containing “IMHO” marker. These are self-labeled claims.
- Transfer learning. Three steps of ULMFit:
- LM on general domain
- Task-specific fine-tune the LM, on IMHO dataset
- Then train/test classifiers.
- Potential model bias? e.g., some premises are mis-classified as claims.
Joint Multiple intent detection and slot labeling for goal-oriented dialog
- Gangaharaiah and Narayanaswamy
- Identify the intent (sentence classification task) and slot label (sequential labeling problem)
- Intents are predicted both at the sentence level and at the token level. The predictions use LSTM.
- Datasets: ATIS, SNIPS
CITE: A corpus of image-text discourse relations
- Existing datasets: TODO
- This is the first dataset describing discourse relations across text and imagery
- This dataset can be used to train classifiers to support automated discourse analysis
- Dataset is on Github
3F Applications, social media, biomedical NLP
(Hyatt Exhibit Hall)
Detecting cognitive impairments by agreeing on interpretations of linguistic features
(Our poster)
- Groups of linguistic features contain important common informations.
- In a biomedical scenario (i.e., DementiaBank with around 500 data points and 413 linguistic features), using Consensus Networks could reach higher accuracies than traditional classifiers.

Fairseq: a fast, extensible toolkit for sequence modeling
- Open-source, PyTorch-based
- Allows developers to train custom models for translation, summarization, LM, and other text generation tasks.
0604 Tue
Morning poster
Modeling document-level causal structures for event causal relation identification
Text similarity estimation based on word embeddings and matrix norms for targeted marketing
- Why normalize over the matrix norms? Because you want to collapse out those frequent words while preserving those with the largest eigenvalues.
5A: Multilingual NLP
(11-12:30, Nicollet D)
Detecting dementia in Mandarin Chinese using transfer learning from a parallel corpus
- Dataset:
- DementiaBank: 551 samples
- Lu corpus: 49 picture description samples. Not enough data here.
- Idea: extract features separately, learn find correspondences from out-of-domain data!
- Movie subtitles: OpenSubtitles corpus contain aligned subtitles in 62 languages.
- Proposed model: feature transfer model trained on OpenSubtitles + English features model (previous work).
- Evaluation: mandarin features -> English features (using the feature transfer model), then use the previous work models.
- How to do feature transfer?
First select the top-k features, ordered by $R^2$.
Then take the corresponding features. - Plot: number of best features and the resulting evaluation results (Spearman rho, with the predicted scores)
- Ablation study: how many parallel sentences are needed?
- Summary: we can leverage an out-of-domain parallel corpus to detect dementia in Mandarin Chinese.
Cross-lingual visual verb sense disambiguation
- Task: word sense disambiguation with images.
- Crosslingual visual sense disambiguation
- visual model: ResNet features
- textual model: avg of word2vec embeddings as features
- multimodal model: merge visual and texual features using early fusion
- Crosslingual VSD results
- Example of the results
- Evaluation: multisense dataset with image descriptions
- Crosslingual VSD and MT examples
- Summary: can use imagees to disambiguate senses across languages
Subword-level language identification for intra-word code-switching
- Task: classify the languages (language identification, LID)
- When the words consist of morphemes from multiple languages, code-switching is more common when languages are morphologically rich.
- Model: end-to-end model based on segmentational RNN.
MUST-C: a Multilingual speech translation corpus
- Motivation: paradigm shift in MT
- Data source: TED talks
Contextualization of morphological inflection
- What is morphological inflection?
- Task: predict the fully inflected sentence from its partially inflected version.
- Model: Neural CRF with an RNN potential.
- Experiment data: universal dependencies v1.2
- Baseline: SIGMORPH, BiLSTM (Cotterell et al., 2018)
A robust abstractive system for cross-lingual summarization
- Problem: summarization
- Approach:
- Train a baseline abstractive summarization system on NYT (English) annotated corpus
- Automatically translate NYT articles into a low-resource language and back to (noisy) English
- Pair the synthatic “translations” with the clean English NYT reference summaries
- Train robust summarization systems using these pairs.
- Baseline abstractive summarizer: pointer-generator network with coverage vector
- Machine translation: Marian framework. The low-resource languages are Somali, Swahili, and Tagalog.
- Summarization: seq2seq with copy-attention and coverage.
- Pretrain on unmodified NYT (12 epochs)
- Train 8 epochs on “noisy” NYT
- Evaluation on ROUGE-1, ROUGE-2, and ROUGE-L
- Ssanity check on a held-out test set of 6k “translations” from each language
- Real world evaluation: 20 weblog entries from each language. Use 5 human evaluations per article. Score on content and fluecy etc..
Keynote 2: When the computers spot the lie and people don’t
(2-3pm, Nicollet Ballroom. Prof Rada Mihalcea)
- Deception precedes language
“The ultimate goal of learning fo speak might be lying” (Jean Aitchison 1996) - Deception is very frequent (around 2 lies per day. lol)
- Deception is very diverse
Diverse reason for lying. Humans are poor lie detectors
-> We should look at the difference between behavioral and true clues.
4.1 Standatd data annotation strategies do not work
4.2 Deception detection is not a big data problemDeception (detection) is central to many domains
Deception (detection) has many social implications
- Ethics and bias
- Are they ready for massive use? Need large-scale experiments.
- Misinformation
6D: Question answering
(3:30 - 5pm, Nicollet B/C)
Improving machine reading comprehension with general reading strategies
- Focus on several strategies:
- Go back and forth in the text to find relationships among ideas
- Highlight information in the text
- Ask myself questions I would like to have answered in the text, then check to see if my guesses about the text are right or wrong.
- Back & Forth reading: consider both the original and reverse order of an input sequence. (Fine-tune two pre-trained LMs, but the token-level sequneces within each sentences are preserved.)
- Highlighting: add a trainable embedding during fine-tuning (basically giving it a special emb value if the POS belongs to the “content words” set).
- Ask myself questions: self-assessment
- Evaluation: RACE (reading comprehension Q&A dataset)
- Open-sourced the codes.
Multi-task learning with sample re-weighting for machine reading comprehension
- Problem: Machine Reading Comprehension (MRC) do not have too much data.
- Previous approaches to augment data: language modeling, etc.
- Propose method: multi-task learning. Multi-Task Stochastic Answer Network
- MLT training algorithms:
- Basic training: randomly pick dataset, then randomly shuffle minibatches. Problem: negative transfer.
- Mixture Ratio. In each iteration, randomly ly pick a fraction of external dataset and add to the chosen dataset.
- MTL with sample re-weighting.
- Evaluation on SQuAD and NewsQA.
- Open-sourced the codes.
Iterative search for weakly supervised semantic parsing
- Presentation: “this work in one slide” summary.
- Task: semantic parsing: translating utterances into program-executable sentences.
- Training semantic parsing with denotation-only supervision is challenging because of spuriousness: incorrect logical forms can yield correct denotations.
- Two solutions:
- Iterative training
- Coverage during online search. Coverage is a measure of relevance of the candidate logical form $y_i$ to the input $x_i$, in terms of how well the productions in $y_i$ map to parts of $x_i$.
- Got SOTA single model performances: WikiTableQuestions with comparable supervision, and NLVR semantic parsing with significantly less superivsion.
Alignment over heterogeneous embedings for QA
- Task: QA (multiple choice)
- AHE architecture:
- Aligns each word in question and answer to its most similar word in the supporting paragraphs.
- The supporting paragraph is retrieved using an off-the-shelf IR tool
- Embeddings considered: FLAIR (char-based), BERT (word-based), InferSent (sentence-based). Ensemble the results from all three embeddings.
- Evaluation: ARC (AllenAI’s reading comprehension), WikiQA
- Further analysis: (1) How complementary are the representations? (2) How well does the model transfer between domains? (3) Manually analyze some questions that AHE model gave incorrect results.
0605 Wed
Morning keynote: Building NLP applicaitons that real people can use
(9-10, Nicollet Ballroom)
About textio.com:
- Your language reflects your culture.
7F: Posters
(10:30-12:00 Exhibit Hall)
Segmentation-free compositional n-gram embedding
- Given a sentence, look at all its subword components, and then output one embedding vector.

Misspelling-oblivious word embeddings
- Based on FastText, but add the spelling correction loss $L_{SC}$.
- FastText (word2vec) loss encourages word & subwords within the context of each other to stay closer.
- $L_{SC}$ encourages tokens and their common misspells to stay close to each other.
- How to generate mis-spelled words? Mine the query search logs of facebook.
- Evaluation: intrinsic (similarity and analogy) & extrinsic (POS tagging ). The misspelled words are also mined from search engines.

Understanding learning dynamics of LMs with SVCCA
- SVCCA = SVD (to reduce latent vectors dimensions) + CCA (to check the similarity between LSTM LM and a tagger)
- Intermediate layers become similar to a tagger during training, but the embedding layers are different.

Continual learning for sentence representations using conceptors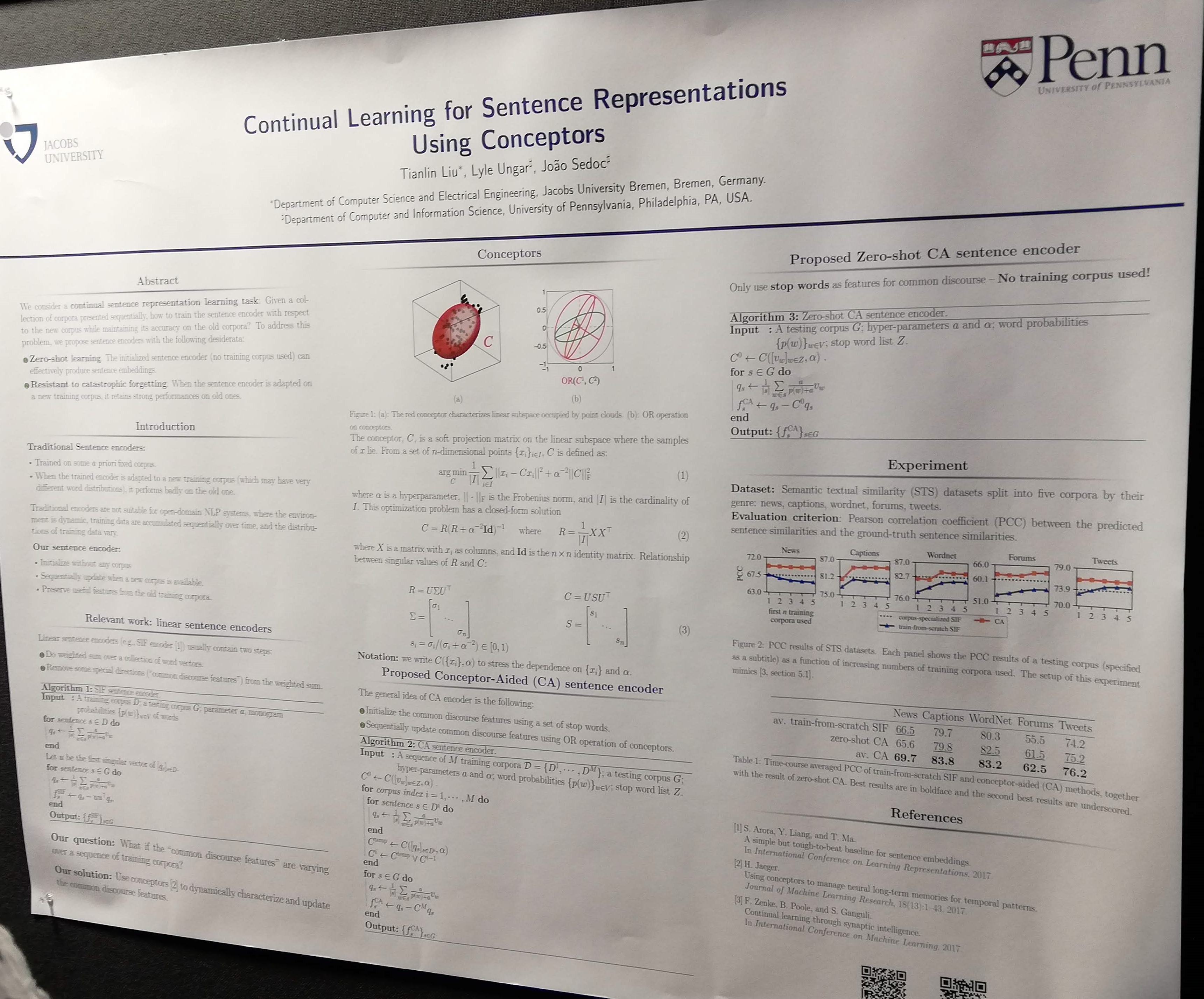
Investigating robustness and interpretability of link prediction via adversarial modifications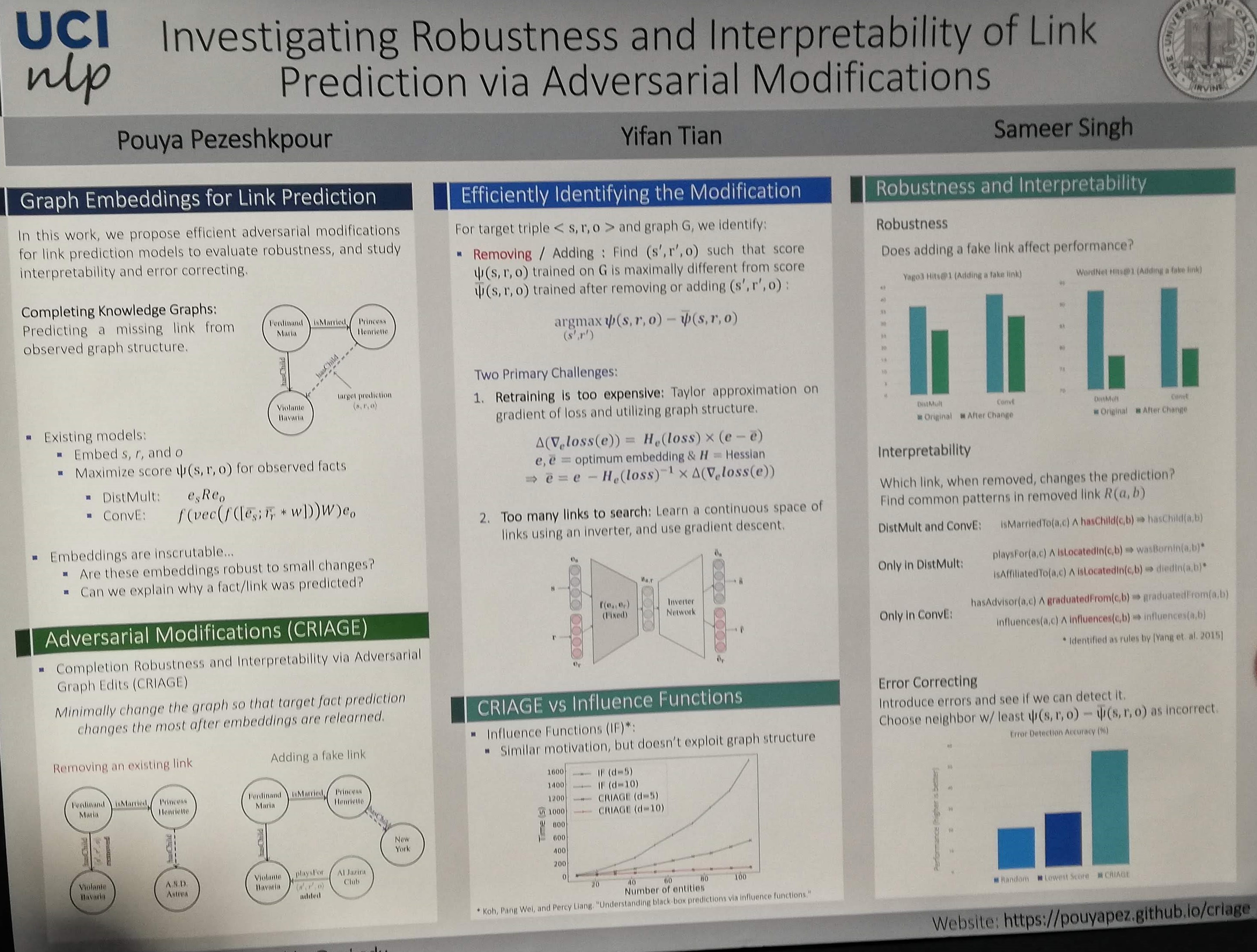
Analysis methods in NLP: a survey
- Visualization
- Finding linguistic information in neural models
- Finding challending sets
- Adversarial examples
- Explaination

Gating mechanisms for combining char and word-level word representations: en empirical study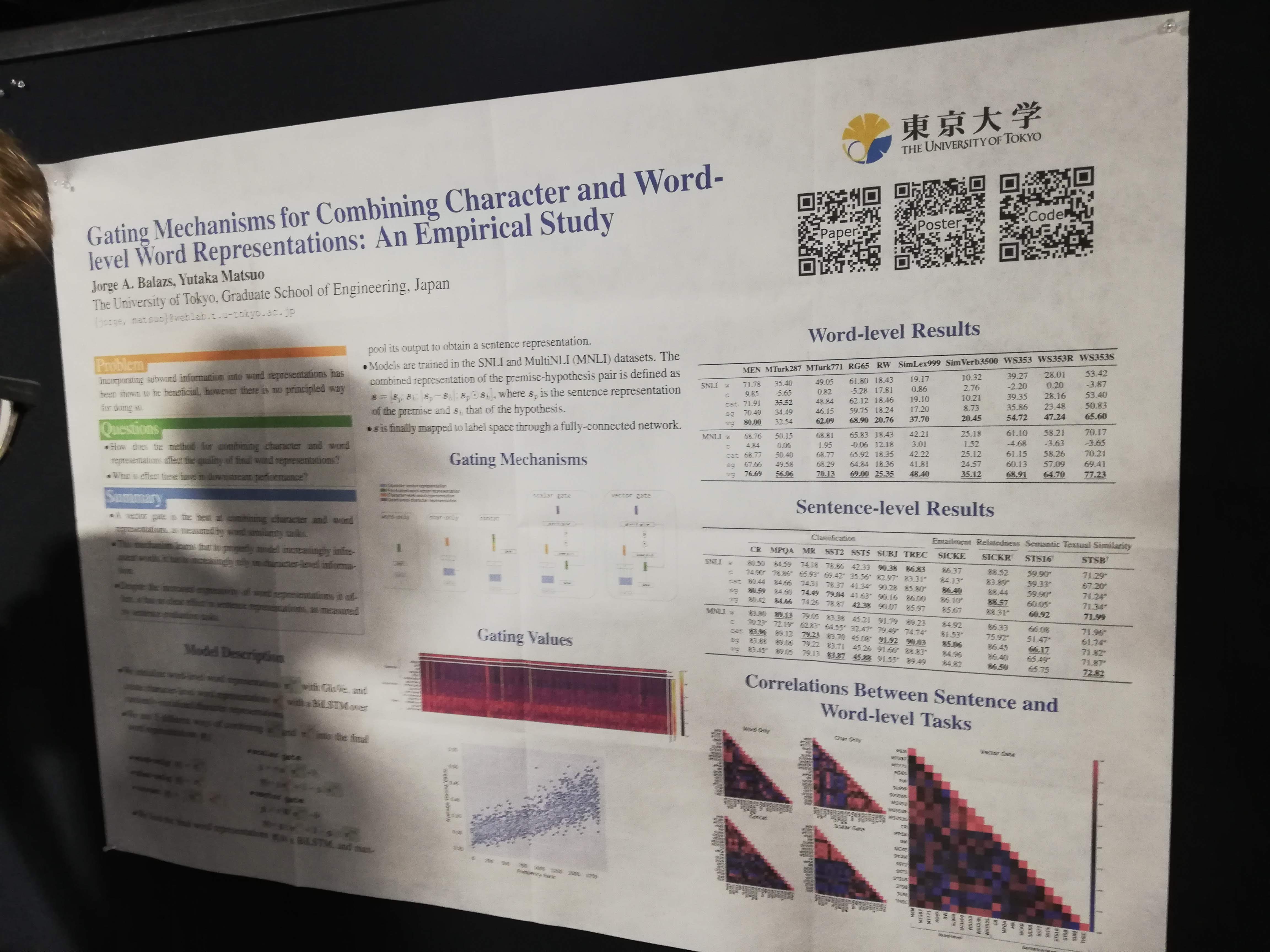
Neural text normalization with sub-word units
8E: Bio & Clinical
(1:30-3pm Nicollet D)
Multilingual prediction of Alzheimer’s disease through domain adaptation and concept-based language modelling
- Transfer results from English AD detection dataset into French (much smaller)
- Identify a set of transferrable features
- Information content units
- info features
- LM-derived features
Ranking and selecting multi-hop knowledge paths to better predict human needs
- Research in sentiment analysis
- Show that integrating commonsense knowledge help the model to better predict human needs.
- Contributions:
- Selecting and ranking multi-hop relation paths from a commonsense knowledge resource.
- end-to-end model enhanced with self-attention and a gated knowledge integration component to predict human needs.
- Knowledge paths provide interpretability.
NLP whack-a-mole: challenges in cross-domain temporal expression extraction
- Goal:
- evaluate performance of Chrono on a clinical corpus (Newswire dataset) before and after algorithm improvements.
- Identify parsing issues.
- Background: temporal resolution: extracting, normalizing, and interpreting temporal information in text.
- Subtasks: (Chrono focuses on) temporal expression identification
- Temporal representation: SCATE vs TimeML
- Evaluation:
- Precision, recall, F1
- 100% vs span-only
- Sumary:
- Identify 6 domain shift challenges:
- Ditribution of entity types
- Lexical diversity
- Frequent frequency
- Disambiguating dosage
- Cross-domain ML training data
- Lexical variation
- Document structure
- Identify 6 domain shift challenges:
- Chrono’s web interface: here
- Slides here
Document-level N-ary relation extraction with multiscale representation learning
- Task: N-ary relation extraction
- Goal: assist expert curators.
- Attempt 1: …?
- Attempt 2: Binary decomposition
- Attempt 3: Full document model
- Model scores every triple of (drug, gene, variant) in the document
- Multiscale combination
Inferring which medical treatments work from reports of clinical trials
- Prediction task: Given a prompt and an article, produce an answer and the rationale.
- Dataset: Full-text articles describing RCTs.
- Present a new corpus (this above dataset).
- Website here
9D: Cognitive & Psycholinguistics
(3:30-4:30pm Nicollet D)
SNAP-BATNET: Cascading author profiling and social network graphs for suicide ideation detection on social media
- Created a large dataset
- Motivation: suicide as a social problem. The correlation between social media use and suicidal.
- Dataset: keyword; author profiling; feature design and extraction (e.g., TF-IDF, POS counts, NRC emotion, GloVe embedding, LDA);
- Text-based models
- Author-based models
- Combining social graphs
- Final model: SNAP-BATNET. Used a meta-learner to combine the predictions made using each feature set. Useful in combining feature sets of different distributions.
A large-scale study of the effects of word frequency and predictability in naturalistic reading
- Goal: show if there are separable effects of frequency and predictability in naturalistic reading.
- Naturalistic reading: …?
- Frequency is depicted by unigram log probability
- Predictability is characterized by 5-gram surprisal
- Result: either of frequency and predictability affects naturalistic reading, but there is no evidence of separable effects.
Augmenting word2vec with LDA within a clinical application
- Add LDA information into linguistic feature vectors
- And then classify dementia
On the idiosyncrasies of the Mandarin Chinese classifier system
- Classifiers encode an oncology. e.g., “支”,“块”,“条”. (This is not the ‘classifier’ in ML classifiers)
- “Classifier system display many of the imaginative aspects of mind, especially the use of mental images
(Lakoff, 1987)- Question: how idiosyncratic is the Mandarin chinese classifier system?
- Method: compute the mutual information between the classifiers and nouns (expect this MI to be highest), and classifiers and adjectives (should be >0), and I(Classifiers; Synsets - This are lower than the previous two).
- Dataset: Chinese Gigaword corpus
- Parse: Google’s pretrained Parsey Universal. Then obtain empirical distributions of classifiers, nouns and adjectives.
(another session) A structural probe for finding syntax in word representations
- Want to test whether syntax trees are encoded in linear projections of word embeddings vectors.
- The linear probe model (parameterized by the matrix $B$ in the paper): given a sequence of words, output a sequence of vectors.
- To optimize, let the (L1) pairwise distance between word vectors go towards the tree distance between words in syntax trees.
- Distance between word vector: $(B(h_i - h_j)^T (B(h_i - h_j)))$
- Tree distance within words syntax trees: For neighbors, $d(u,v)=1$.
- Also considered parse depths besides tree distance.
- How to tell if an embedding has encoded the tree structures?
- For tree distance: Undirected Unlabeled Attachment Score (UUAS), avg Spearman correlation.
- For parse depth: root prediction accuracy and avg Spearman correlation.
Best paper session
(4:45 - 6:15 Nicollet Ballroom)
CNM: An interpretable complex-valued network for matching
(Best explainable paper. Li et al)
- Research problem: interpretability issue for NN-based NLP models. According (Lipton ‘16):
- Transparency: explainable component in the design phase
- Post-hoc explainability: why the model works after execution
- Motivation: Quantum Theory is beneficial to model uncertainty.
- Related work: Existing quantum-inspired models for NLP and IR tasks.
- Proposal:
- A unified quantum view of different levels of linguistic units
- Sememes
- Words
- Word combinations
- Sentences
- An end-to-end complex-valued network
- Numerically constrained components
- Explainable as quantum concepts
- A unified quantum view of different levels of linguistic units
- Quantum preliminaries:
- Hilbert space: inf dimensional.
- Pure state: basic state / superposition state. Mixed state: to describe a set of quantum particles.
- Measurement
- Uncertainty in language vs. uncertainty in QT
- Single word <-> uncertainty of a pure state
- Multiple words <-> uncertainty of a mixed state
- High-level semantic models <-> Hilbert Space features
- Application to text matching.
- CNM: network structures
- Experiment datasets: TREC and WikiQA: select the most similar candidate answer given a question.
- Post-hoc explainability
CommonsenseQA: A QA challenge targeting commonsense knowledge
(Best resource. Talmor et al)
- Common sense in NLP example: Winograd Schema challenge.
- Problem: reporting bias
- Conversational maxim of quantity: communication should be as informative as necessary but no more than required (Grice’s maxim)
- Possible solutions
- Human annotation
- Machine implicitly learning
- Goal:
- Generate a challenging dataset for commonsense reasoning.
- How to avoid human bias? Solution: use ConceptNet as a “seed”, then let human annotators do multiple choice questions.
- Contributions:
- A new method for generating commonsense QA dataset.
- Experiments and baselines
- VecSim
- ESIM (Chen et al., 2016)
- BIDAF++
- GPT / BERT: sentence [sep] answer -> one logit.
- Human performance. Much better than all previous models.
- CrowdSence: Website and Demo
Probing the need for visual context in multimodal MT
(Best short paper. Caglayan et al)
- Task: multimodal machine translation
- Dataset: Multi30k.
- Potential benefit:
- Language grounding (sense disambiguation, grammatical gender disambiguation, new concepts)
- Images doesn’t help yet. In this paper we show this is because the Multi30k dataset is too simple.
- We degrade source language (e.g., color masking, entity masking, progressive masking)
- Hypothesis 1: MMT models should be better than text-only models if image is effectively taken into account.
- Hypothesis 2: more sophisticated MMT models should perform better than simple MMT models.
- Experiments: the effects of masking (color / entity), progressive masking. Also compared attentive MMT vs. simple INIT grounding.
BERT: pretraining of deep bidirectional transformers for language understanding
(Best long paper. Devlin et al)
- Pre-training task: language modeling
- Downstream task: fine-tune on various language understanding problems
- Model structure: multi-layer bidirectional model, which is the Encoder of Transformer. Note: in the Vaswani 2017 paper, their “Transformer” is an encoder and a decoder. BERT only takes the encoder component.
What’s in a name? Reducing bias in bios without access to protected attributes
(Best thematic paper. Romanov et al)
- Task: classify occupation from the people’s online bibliography, but discourage the correlation between the prediction and a word embedding of their name.
- Method: add a constrained loss to the optimization target: either of cluster CL or covariance CL.
- Cluster CL: average pairwise distance of the cluster centroids of name vectors (embeddings of names).
- Covariance CL: the covariance between prediction of a data point and the individual name vector.
- Evaluation:
- Datasets: Adult income dataset from UCI, and Bios dataset (De-Arteaga et al, 2019)
- Quantifying bias: true positive rate (TPR) race gap and TPR gender gap.
0606 Thu SemEval and *SEM
Task-independent NLU models
(9:30-10:30, Sam Bowman, Great Lakes A)
A general-purpose sentence encoder tries to encode the semantics in the reusable network components.
- The upper layer can be trained with relatively small task-specific data -> “What do the labels in this task mean?”
- Case study: ELMO
The GLUE language understanding benchmark
- General Language Understanding Evaluation
- 9 tasks as diverse as possible: WNLI, RTE, MRPC, STS-B, CoLA, SST-2, CoLA, QQP, QNLI
- All sentence (or sentence pairs) classification
The successes with unsupervised pretraining and fine-tuning on GLUE
The updated SuperGLUE benchmark
- paper
- The downloading scripts, etc. are accessible through the Jiant toolkit
Easy transfer learning with STILTs
A few more thing we’ve learnt with these models
- Nothing works significantly better than language modeling
- Pre-training helps.
- The correlations between these tasks are low. The models tend to be task-specific.
- Another view: edge probing. To what extent are ELMo and BERT already doing syntactic / semantic tasks? (ICLR 2019)
Task 1-3 presentations
(10:30-12:30 )
Task 1: Cross-lingual semantic parsing with UCCA
Task 2: Unsupervised lexical frame induction
- Task A: identifying semantic frames
- Task B.1 “full” frame semantic tagging (WordNet roles)
- Task B.2 Case role labeling (VerbNet roles)
- Dataset: WSJ corpus (PTB) 3 annotators
Task 5-6 presentations
(14:00-15:00)
Task 5: Hate speech detection
Task 6: Offensive speech detection
Poster
(15:00-15:45 Exhibit Hall)
DISRPT session
(16:00-17:30 Nicollet D3)
Towards discourse annotation and sentiment analysis of the Basque Opinion Corpus
- Basque opinion Corpus:
- 240 opinion texts collected from different websites
- Domains: sports, politiss, music, moves, etc.
- Methodology steps:
- Set the stage for the annotating work
- Annotation procedure and process: (Das and Taboada, 2018). Follow a parse algorithm to build up a tree (leafe nodes are sentences).
- The structure reveal some information about the sentiments. e.g., “In CONCESSION relations,
the semantic orientation of the nucleus always prevails but the valence of the satellite must also be
taken into consideration. In EVALUATION relations, words with sentiment valence concentrate
on satellite.”
Using rhetorical structure theory to assess discourse coherence for non-native spontaneous speech
- Background: SpeechRater
- Goals:
- Annotate spontaneous spoken corpus using RST
- Develop an automatic RST parser
- Derive discourse features from RST trees
- Use RST-based features for non-native speech scoring
- Derive 8 features from RST theory
Applying rhetorical structure theory to student essays for providing automated writing feedback
- RST: Rhetorical structure theory (a descriptive theory about the structures of the text)
- Decide nuclearity flowchart
- Open sourced the annotation guideline & flowchart: http://tinyurl.com/RSTguideline
0607 Fri
Morning talk at ClinicalNLP
Enhancing quality and robustness of biomedical information extraction
(9:15-10:30 Nicollet D1)
Problem: there are too much data and too little time.
Overall goal: build knowledge network to accelerate scientific discovery
Background: entity extraction and linking
- Abstract meaning representation for mentions
- Entity linking to 300+ biomedical ontologies. E.g., document-level co-occurrence graphs
- Aiming for higher quality: supervised approach to entity extraction. e.g., CRF+LSTM
Moving from biomedical literature to clinical notes: informal and contains many ambiguous abbreviations
- Supervised models are very fragile: moving from formal genre to informal genre.
- Solution: make supervised models more robust.
- Context-aware relation extraction. e.g., using GCN etc.
AMR-based unsupervised event extraction
Application in speeding up scientific discovery
- Create new ideas
- Write a new paper about the new ideas (e.g., PaperRobot in ACL 2019). Predict links between nodes -> follow the templates -> generate incremental paper
- Link prediction on top of IE
- Repetition removal: Use a coverage loss to avoid any entity in reference input text or related entity receiving attention multiple times
- PaperRobot could help researchers generate drafts. Some profs translate students’ PPTs into paper drafts -> could relieve this work.
- This approach does not work for NLP yet. Don’t have enough data.
Discussion about evaluation metrics in NLP
- If e.g., the accuracy reaches 90% we should probably stop working on it and shift to other datasets. 2 percent of accuracy might not mean a lot. More scenarios should be explored.
Presentation session 1
(11:20 - 12:30 Nicollet D1)
Effective feature representation for clinical text concept extraction (Tao et al)
- Background: crucial information of healthcare recorded only in free-form text.
- Datasets:
- Scientific: pubmed
- CLinical: diagnosis detection prescription reasons
- Social: penn adverse drug reactions
- Commercial: drug-Disease relations
- chemical-disease relations
- Problem: the size of dataset is small
- Task: clinical text annotation
- Diagnosis detection: positive symptoms / concern
- Predcription reasons: prescribed drug; and reason
- Penn Adverse drug reactions: “ADR”
- etc…
- Previous methods:
- LSTM-CRF: general text
- HB-CRF: applied to clinical text. Gathered sparse hand-built features.
- Propose combined model:
- ELMo-LSTM-CRF-HB. Dense ELMo word embeddings + sparse hand-built features.
- Evaluation: per-token macro-F1 scores
- Baselines:
- rand-LSTM-CRF (randomly initialized word embeddings + LSTM)
- HB-CRF
- ELMo+CRF
- etc.
- Experiments:
- The role of text length. LSTM handles short texts well. HB-CRF is however robust on long texts.
- Inspect the CRF potential scores. See which features are more important. -> LSTM features are always more important; HB features make substantial contribution as well.
- The major improvements of proposed models come from minor categories.
An analysis of attention over clinical notes for predictive tasks (Jain et al)
- How to encode clinical text? Desiderata:
- Predictive performance
- Transparency
- Correct causal modeling
- Tasks and datasets:
- MIMIC III: three tasks of it
- Surgical notes for hip / knee arthroplasty: predict 30 day re-admission
- Evaluation: predictive performance.
- Models: Logistic regression, BiLSTM, Bi-LSTM with attention (either softmax or logodds as attentions -> logodds are better at both train and test).
- Transparency: attention is explanation (e.g., weights of importance) or not?
- Causal modeling: counterfactual experiment. Attention permutation experiment.
- Takeaway:
- LogReg provides competitive baseline
- Hidden state aggregation using attention or max pool are important for neural models
- Transparency could be a tradeoff in neural models
- Attention does not solve transparency issues.
Extracting adverse drug event information with minimal engineering (Miller et al)
- Background: adverse drug events from clinical notes
- Items for the Track 2 in 2018 n2c2 challenge
- Drug and attribute extraction (NER)
- Relation classification (gold entities)
- Relation extraction (end2end)
- Goal:
- pre-challenge: benchmark standard info extraction approaches
- post-challenge: compare neural vs feature-based methods
- general: build systems for ADE extraction
- Minimal engineering
- Traditional system: SVM-based relation system
- Neural methods: use FLAIR (because it’s char-level and has easy-to-use API) as embedding, Use modified form of xml representation from Dligach et al (EACL 2017).
Hierarchical nested NER
- Task: we want to detect entities within entities (NER within NER), especially those within medical texonomies
- Model: based on Yang et al (2015). Sequential model which transverses the input text and predicts and action per step.
- Dataset: word stack.
- At each step, the model predicts one of the four actions: (1) transition, (2) shift, (3) reduce (“ends the mention I started”), and (4) out (to ignore the word)
Presentation session
(14:00 - 15:30 Nicollet D1)
Towards automatic generation of shareable synthetic clinical notes using neural language models
A novel system for extractive clinical note summarization using EHR data
- Extractive summarization for unstructured clinical notes.
- Baseline: SVM-linear, CRF (linear chain), CNN, Bi-LSTM-CRF.
- Proposed model: break down the problem into separate components.
A BERT-based universal model for both within- and cross-sentence clinical temporal relation extraction
Publicly available clinical BERT embeddings
- Compared BERT, BioBERT and BERT-MIMIC