We are running out of data — the computational power is growing faster than the data, especially high-quality data. It’s time to give more attention to studying the data. This paper presents a framework to study the effects of data during multitask training. Our framework allows quantifying the individual effect of a dataset, as well as the interaction effects between two datasets. Spoiler alert: some datasets can interact with each other in a potentially undesirable way!
Why study the data effects?
Many large models are not trained on one single dataset. They are trained on a lot of datasets — The Pile (which trained GPT-3) contains over 800GB texts, and consists of 22 smaller datasets. RedPajama (which trained OpenLLaMA) contains over 5TB texts, and contains many datasets like Common Crawl, C4, GitHub, Books, and Wikipedia.
Everybody just combines the datasets, but what are the effects of combining these datasets? Will combining these datasets lead to potentially undesired outcomes? If yes, how to quantify this effect?
An analogy: taking courses
Let’s consider a semester in the university. A student, Bob, can choose to take some courses.
Imagine Bob only takes math in the past semester. He learned calculus. He can solve some differential equations. He gained analytical reasoning abilities. These changes in the abilities are the effect of the math course.
Using the differential equations, Bob is able to handle some physics questions. There are also some effects that appear to be less relevant to the math itself. Bob might know history better, for example, if the math course instructor told the anecdotal stories of L’Hôpital and Bernoulli. The effect of the math course can go beyond STEM subjects themselves.
Now, what if Bob takes two courses — math and physics. After the semester, will the abilities to write reports be strengthened? Will the memory about linguistics be forgotten? The effects of multiple courses may go beyond the summation of the individual effects.
How to know if the abilities of Bob have changed, and if yes, how much? We can apply two standardized exams — one before the semester, and the other one after. The changes in the exam scores describe the changes in the abilities along each of the dimensions.
Coming back to the language model training problem. The university semester is an analogy of the training procedure. Bob is an analogy of the language model. The exam scores are analogies of a technique that we have been working on for several years: probing.
A framework to describe the dataset effects
Let’s first idealize the probing tests — we assume each score perfectly represents the ability of the model at the time of exam. The collection of exam scores constitute of a vector that describe the state of the model. This is the state-vector.
We run the standardized exams (“probing”) on the model twice — once before training (“semester”), and the other time after. If the semester contains only one dataset (“course”) , then the vector difference of the two state-vector describes the effect of this dataset. We call it the individual effect .

The individual effect is a vector pointing from the initial state to the ending state .
Similarly, imagine there is another dataset . Training on the dataset can bring the model from to state .
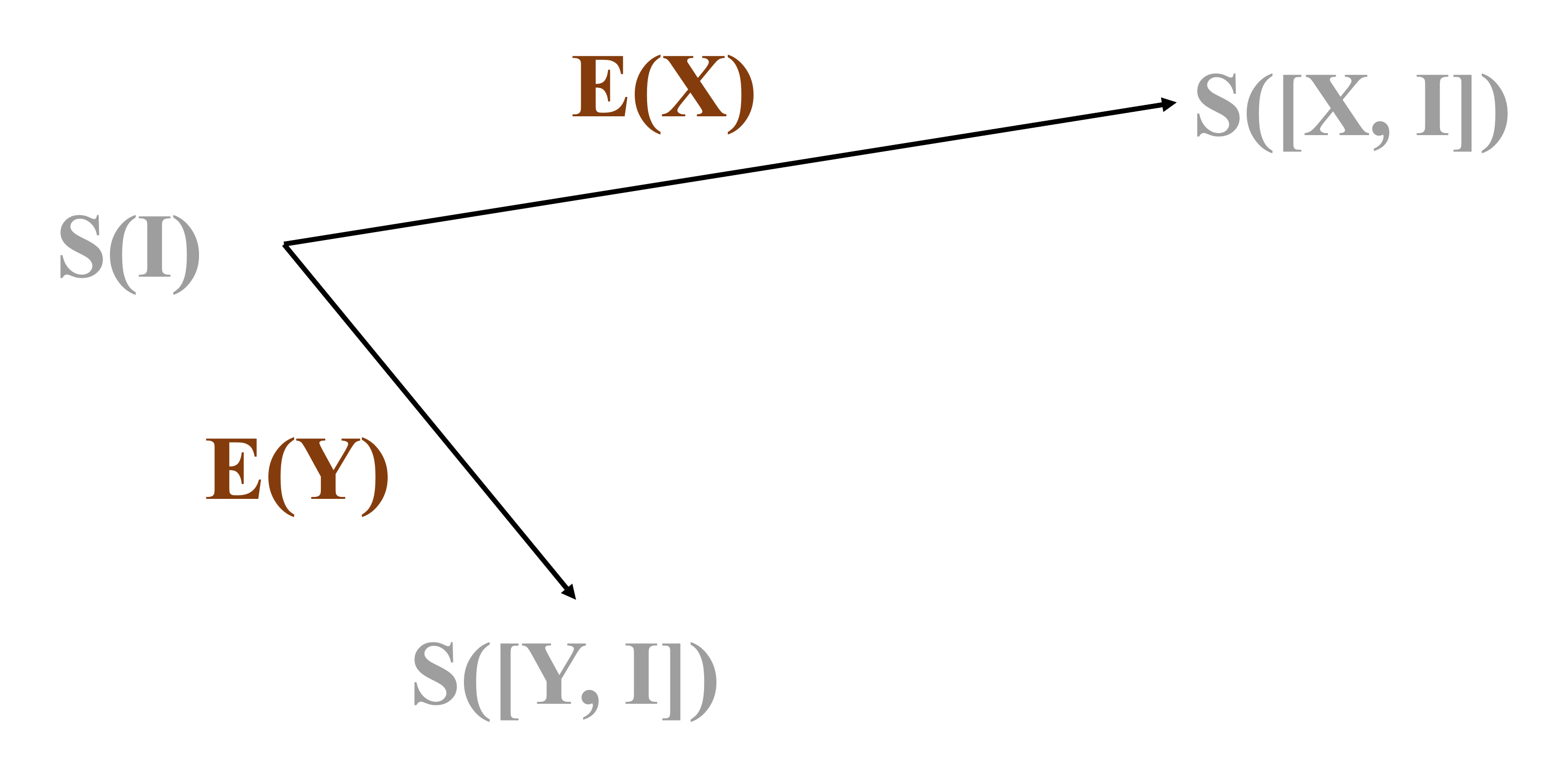
Putting and together. If and has no interaction at all, then the change in the model ability should be the vector sum of the two individual effects.
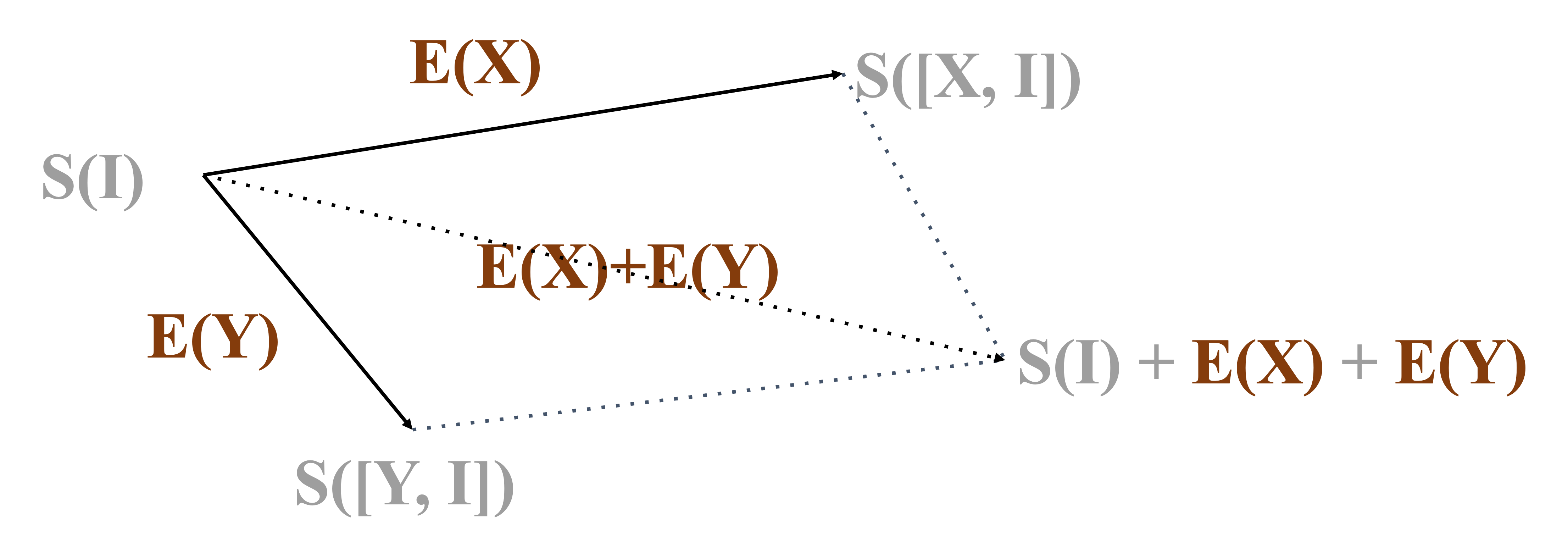
However, in reality, if we train the model on and combined, the resulting state usually differs from the location marked — the model instead goes to .
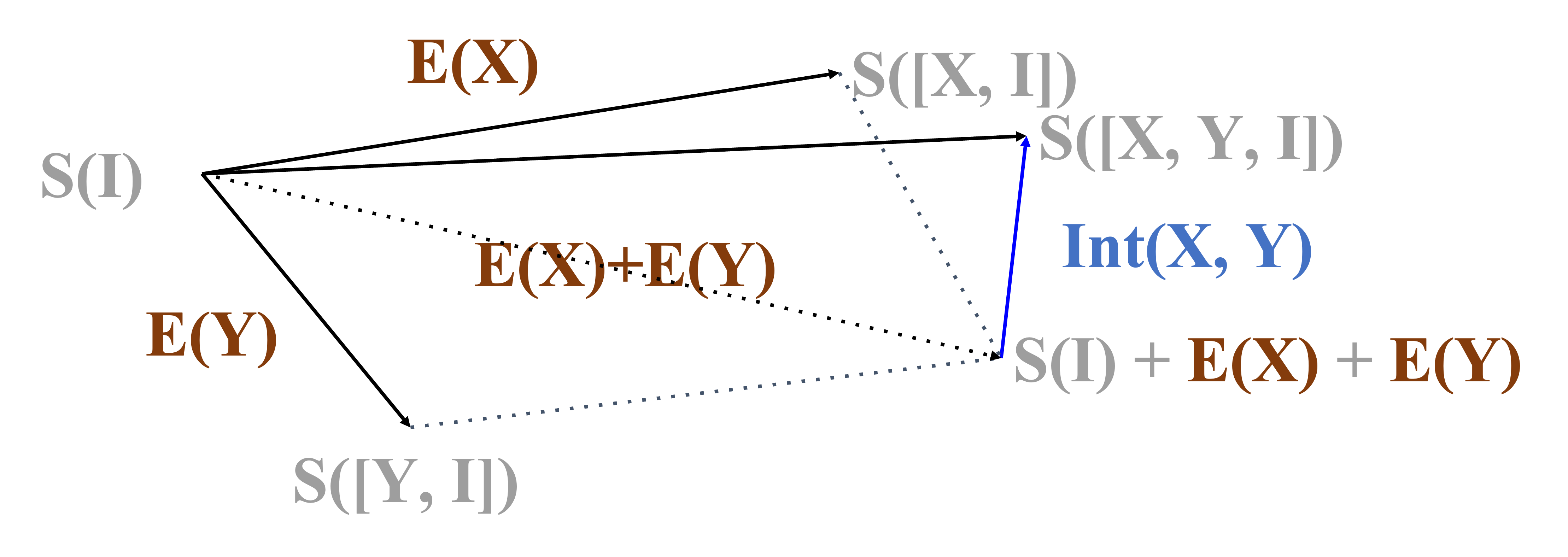
The vector difference between where the model should go and where the model actually ends up at is the interaction effect.
In the paper, we defined the individual effects and the interaction effects with math formulations. Our formulation supports statistical testing — you can compute a -value. When it is smaller than 0.05, the dataset effect is significant.
Experiments
In experiments, the state comes from probing. Currently, the probing techniques are not 100% valid — I discussed the validity from an information-theoretical view in EMNLP 2020. The probing techniques are not 100% reliable — I discussed how to make them more reliable in ACL Findings 2022. We probe the models multiple times using different random seeds, so the measured state is a region.
Empirically, we take the center of the region to estimate the dataset effects.
In the figure below, the arrow is the individual effect.
In the figure below, the purple arrow indicates the interaction effects.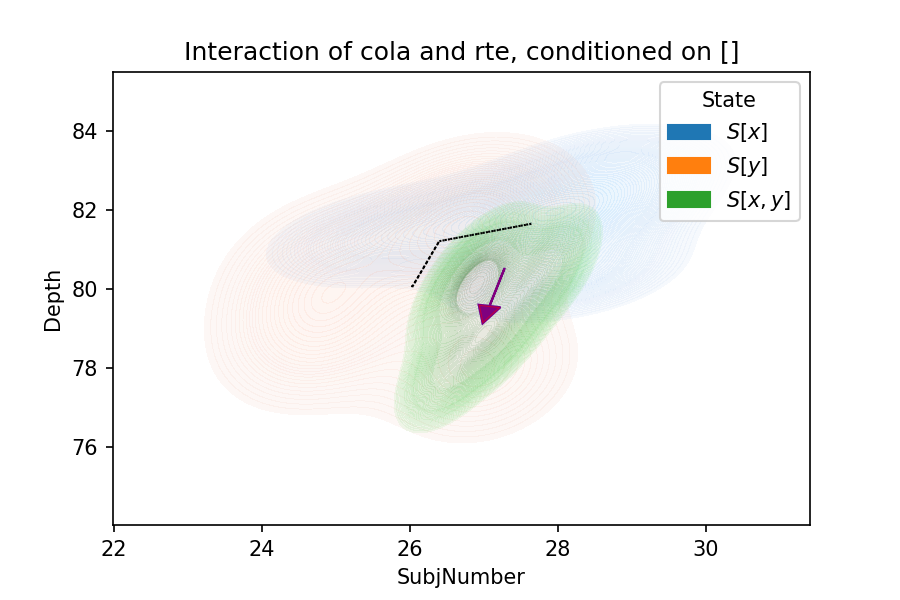
Some observed trends in dataset effects
We observed some really interesting trends in training the models.
Individual effects:
- The individual effects depend on the models.
- Some datasets with very similar tasks impact drastically different dimensions.
- There are some “spill-over” effects, analogous to “a math course improved the writing skills”.
Interaction effects:
- They are concentrated. There are almost never more than 3 dimensions show significant interaction effects.
- They can occur on the dimensions where the components’ individual effects are insignificant.
- They are characteristic. Many datasets have drastically different interaction effects.
- The similar datasets interact less.
Takeaways
- We need to pay more attention to the quality of the datasets.
- One way to study the effects of datasets is to estimate their indiviual and interaction effects.